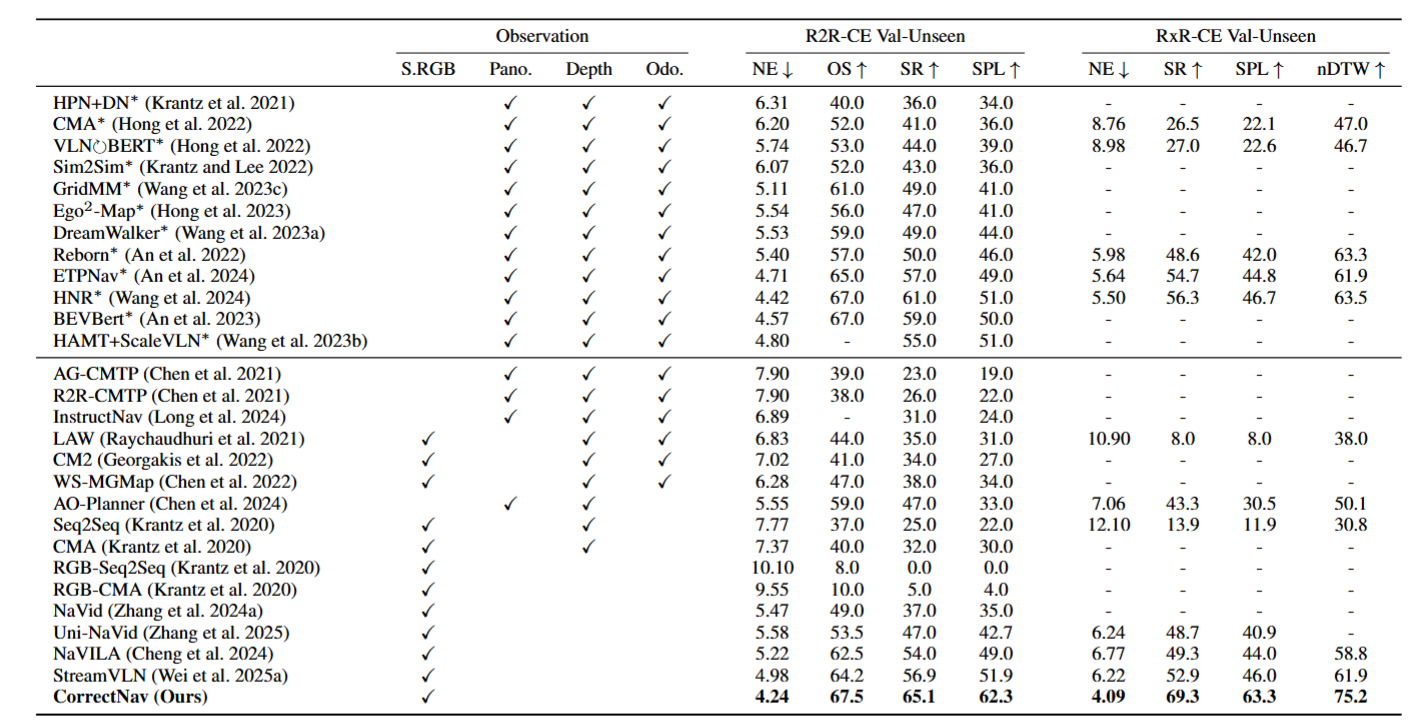
Overview
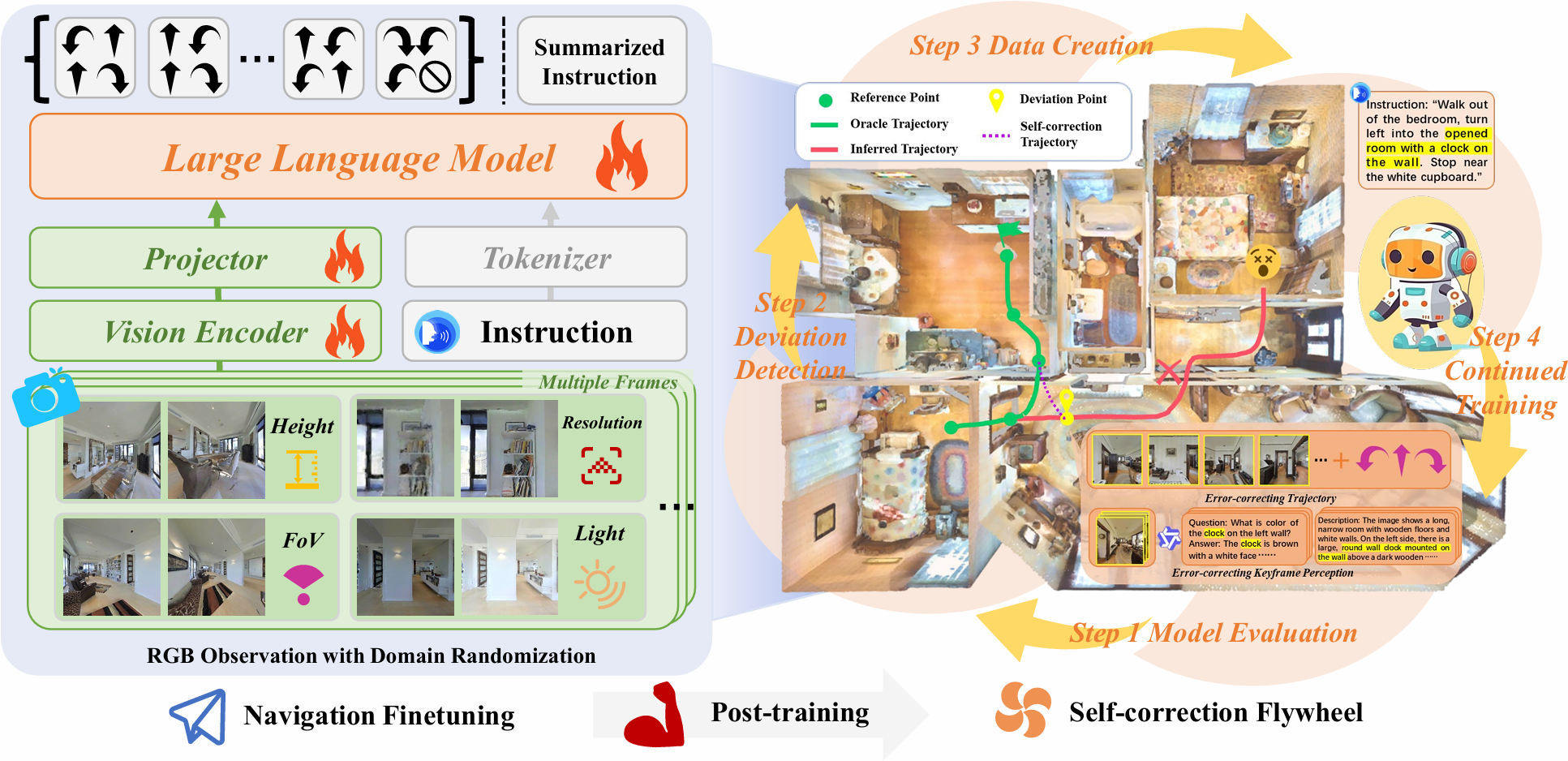
Existing vision-and-language navigation models often deviate from the correct trajectory when executing instructions. However, these models lack effective error correction capability, hindering their recovery from errors. To address this challenge, we propose Self-correction Flywheel, a novel post-training paradigm. Instead of considering the model's error trajectories on the training set as a drawback, our paradigm emphasizes their significance as a valuable data source. We have developed a method to identify deviations in these error trajectories and devised innovative techniques to automatically generate self-correction data for perception and action. These self-correction data serve as fuel to power the model's continued training. The brilliance of our paradigm is revealed when we re-evaluate the model on the training set, uncovering new error trajectories. At this time, the self-correction flywheel begins to spin. Through multiple flywheel iterations, we progressively enhance our monocular RGB-based VLA navigation model CorrecctNav. Experiments on R2R-CE and RxR-CE benchmarks show CorrectNav achieves new state-of-the-art success rates of 65.1% and 69.3%, surpassing prior best VLA navigation models by 8.2% and 16.4%. Real robot tests in various indoor and outdoor environments demonstrate CorrectNav's superior capability of error correction, dynamic obstacle avoidance, and long instruction following.